
Stable Video Diffusionは、AI技術を駆使して動画コンテンツを生成する革新的なツールです。
この技術がどのようにして動画制作の概念を変えているのか、そのプロセスや機能を理解することは、多くのビデオクリエーターや企業にとって価値があります。
本記事では、Stable Video Diffusionの基本概念から始め、その使い方、料金体系、そして商用利用の可能性について詳しく掘り下げていきます。
Stable Video Diffusionとは?

What’s Stable Video Diffusion?
Stable Video Diffusionは、人工知能(AI)技術を駆使して動画コンテンツを生成する革新的なツールです。
現代の映像制作やデザインの分野で非常に注目されているこの技術は、既存の画像や映像を基にして新しいビジュアルコンテンツを生成する能力を持っています。
 ぼー
ぼーつまり、ユーザーはこのツールを利用することで、従来の手法では時間と労力がかかる作業を大幅に効率化し、高品質な作品を迅速に制作することができます。
動画生成のプロセスは高度なニューラルネットワーク技術に依存しており、膨大なビデオデータから学習を行い、このプロセスを通じて、AIはパターンや動き、視覚的な要素を理解し、新しい動画を創出します。
特にStable Video Diffusionは、リアルタイムでのビデオ処理能力に優れており、短時間で高解像度の動画を生成する点で他のツールとは一線を画しており、映像制作において迅速かつ効果的にプロジェクトを進行できるため、クリエイターやデザイナーにとっては欠かせないツールとなるでしょう。
この技術の利用は、映画、広告、教育、エンターテインメントなど、さまざまな分野での応用が期待されています。
ぼーたとえば、映画制作では、特定のシーンの背景や特殊効果の生成に活用することで、現実では実現が難しいビジュアルを手軽に作り出すことができます。
広告業界では、商品のプロモーションビデオを短時間で制作し、市場投入までのスピードを加速させることが可能です。
このように、Stable Video Diffusionは多岐にわたる分野での利用が見込まれており、今後さらにその可能性が広がることでしょう。
Stable Video Diffusionの料金体系

Stable Video Diffusionを利用する際の料金体系は、使用のスケールや目的によってさまざまです。
一般的には、基本的な使用に関しては無料プランが提供されており、初めて利用するユーザーや個人的なプロジェクトに最適ですが、下記にあるように非商業的な目的と研究目的とする利用に限り無料です。


Stable Video Diffusionは商用利用可能?

商業利用や高度な機能を必要とする場合は、メンバーシッププログラムのプロもしくはエンタープライズのプレミアムプランを選択する必要があります。
このプレミアムプランでは、生成する動画の解像度、長さ、使用するサーバーのスペック、APIアクセスの頻度などに応じて料金が設定されています。
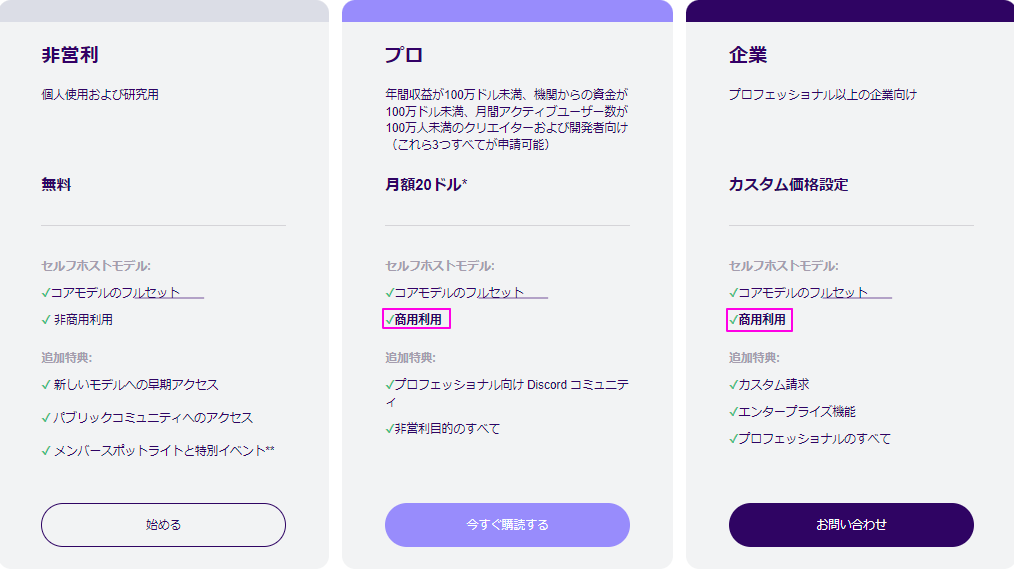
プレミアムプランの料金設定は、個人ユーザーから大規模な企業まで幅広いニーズに対応できるよう設計されています。
たとえば、個人のクリエイターが短いプロモーションビデオを制作するためのプランから、大企業が大規模な広告キャンペーンのために使用するプランまで、柔軟な選択肢が用意されています。
ぼー長期契約や大量使用に対すると割引が提供されることが多く、コストパフォーマンスを重視するユーザーにとって非常に魅力的です!
さらに、Stable Video Diffusionの料金体系には、追加機能やサポートオプションが含まれています。
ぼーたとえば、専門的なサポートを受けたいユーザーやカスタマイズが必要なプロジェクトには、コミュニティの利用やカスタム、エンタープライズ機能の利用などが提供されています。
これにより、ユーザーは自分のニーズに最適なプランを選ぶことができ、予算内で効率的にプロジェクトを進めることが可能です。
また、商用ライセンスには通常、使用する画像や動画の著作権をクリアするための条件が含まれており、法的なトラブルを避けるためにもライセンス条項を事前に確認することが重要です。
必要に応じて、専門家の意見を求めることで、安心して商用利用ができるでしょう。
このように、Stable Video Diffusionはその柔軟な料金体系と商用利用のオプションにより、個人ユーザーから大規模な企業まで、幅広いユーザー層に対応しています。
商用利用を検討している場合は、プランの詳細をよく確認し、自分のプロジェクトに最適な選択を行いましょう。
Stable Video Diffusionの導入方法と使い方
Stable Video Diffusionを導入するためには、まずそのシステム要件を確認し、必要な準備を整えることが重要です。
ぼー基本的なシステム要件としては、高性能な計算資源(GPUやCPU)、適切なストレージスペース、そして必要なソフトウェア環境の構築が挙げられます。
特に、AIモデルを効果的に動作させるためには、最新のGPUと十分なメモリが必要なことや、PythonやJavaScriptなどのプログラミング言語に精通していることも、ツールの効果的な利用において有利です。
導入プロセスの最初のステップとして、必要なソフトウェアとライブラリをインストールしますが、これにはPythonやそのライブラリ、そしてAIモデルを動作させるためのフレームワーク(例えばTensorFlowやPyTorch)が含まれます。
ぼー次に、ハードウェアがAIモデルの要求スペックを満たしているかを確認し、必要に応じてアップグレードを行います。
これにより、動画生成プロセスの速度と効率が大幅に向上します。
Stable Video Diffusionを効果的に利用するためには、まず基本的な操作を理解するためのドキュメントやチュートリアルを参照することが推奨され、ツールの機能や可能性を探り、自身のプロジェクトに適した使い方を見つけることが必須と言っても過言ではありません。
具体的な使い方としては、小規模なテストプロジェクトを実行し、ツールの性能や操作性を確認することが有効で、実際のプロジェクトでのトラブルを未然に防ぎ、効率的に作業を進めることができます。
さらに、Stable Video Diffusionを手軽に試す方法として、オンラインで利用できるデモやトライアルバージョンを活用することも一つの手段です。
簡単にStable Video Diffusionを試す方法

Stable Video Diffusionを手軽に試したい場合は、オンラインで利用できるデモやトライアルバージョンが最適です。
多くのプラットフォームでは、基本的な機能を体験できるオプションを提供しており、ユーザーは自身のデバイスに何もインストールすることなく、AIによるビデオ生成の能力を直接確認することができます。
Huggingfaceで試す
GitHubやHuggingfaceなどの開発者コミュニティからは、初心者向けの簡易版スクリプトや詳細なガイドが提供されており、自分自身で環境を構築し、基本的な動画生成を行うことが可能になります。
ローカル環境構築をする手順
Stable Video Diffusionをローカル環境で使用するためには、いくつかのステップを踏む必要があり、まず必要なソフトウェアとライブラリをインストールすることが重要で、Python、必要なPythonライブラリ、そしてAIモデルを動かすためのフレームワーク(例えばTensorFlowやPyTorch)が含まれます。
これらのソフトウェアをインストールすることで、Stable Video Diffusionの基本的な環境が整います。
ぼー次に、ハードウェアがAIモデルの要求スペックを満たしているかを確認します。
特に、GPUはAIモデルの性能に大きく影響するため、高性能なものを選ぶことが重要ですがご家庭にあるPCパーツでも最大のネックとなるものでもあります。
理由としてはパンデミックに端を発する世界的なパーツ不足や昨今の円安の影響も重なり、価格が30万円前後とかなり高額な物となっています。
そして推奨されるGPUは、NVIDIAの最新のGeForceやQuadroシリーズのようなもので、CUDAコアの多いモデルが望ましいです。
また、メモリは最低でも16GB以上、理想的には32GB以上が推奨され、プロセッサはマルチコアで高周波数のものを選ぶことが重要です。
これらのハードウェアスペックを満たしていることで、Stable Video Diffusionの全機能をスムーズに利用し、高品質な動画生成を実現できます。
ぼーパーツが高すぎなので、買うよりもオンラインのサービスを借りることをおすすめします。
ソフトウェアとハードウェアの準備が整ったら、次にサンプルプロジェクトやチュートリアルに従って最初のテストを実行します。
環境が正しく設定されているかを確認し、提供されているサンプルデータを使用して、実際に動画を生成してみることで、Stable Video Diffusionの操作を覚えましょう。
また、Stable Video Diffusionの公式ドキュメントやオンラインコミュニティを活用することで、より高度な使い方やカスタマイズ方法を学ぶことができます。
ぼーたとえば特定のプロジェクトに合わせたカスタム設定や、高度なエフェクトの追加方法など、詳細な情報が提供されています。
Stable Video Diffusionを使うために必要なスペック
Stable Video Diffusionを効果的に利用するためには、特定のハードウェアスペックが必要です。
これには、高性能なGPU、十分なメモリ、そして高速なプロセッサが含まれます。AI駆動のビデオ生成は計算コストが高いため、これらのハードウェアコンポーネントがプロジェクトの成功に直接影響します。
ぼー上記でも記述しましたが、最高スペックに近いハードウェアスペックが必要です。
これらのハードウェアスペックを満たすことで、Stable Video Diffusionの全機能をスムーズに利用し、高品質な動画生成を実現できます。
また、プロジェクトの要求に応じて、ハードウェアのアップグレードを検討することも有効です。
たとえば、大規模なプロジェクトや高解像度の動画生成を必要とする場合は、より高性能なGPUや追加のメモリを導入することで、作業効率を大幅に向上させることができます。
ローカルに環境構築する場合
Windowsを例にとると、まずインストールしたいフォルダで右クリック時に表示される「ターミナルで開く」をクリックし、下記コマンドを実行します。
git clone --recurse-submodules https://github.com/sdbds/SVD-webui/実行するとダウンロードが始まるのでしばらく待ちます。
ダウンロードが完了したら、下記コードを実行しSVD-webuiフォルダに移動します。
cd SVD-webui移動したら下記を実行します。
git submodule update --recursive --init次にインストールを行うのですが、Windowsの権限関係を過去に編集していないとインストールできないので、下記コードで実行してインストールしてください。
powershell -ExecutionPolicy Bypass .\install.ps1モデルのダウンロード
svd: stabilityai/stable-video-diffusion-img2vid for 14 frames generation NEED 15GB VRAM
svd_xt: stabilityai/stable-video-diffusion-img2vid-xt for 25 frames generation NEED 18GB VRAM
上記モデルを以下インストールしたフォルダ内にある「checkpoints」フォルダにダウンロードします。
インストール場所\SVD-webui\checkpointsGUIの起動
下記コマンドを実行してGUIを起動してみましょう。
powershell -ExecutionPolicy Bypass .\run_gui.ps1以上でローカルへの導入は完了です。
ぼースペックが不足している場合PCがフリーズもしくはハングアップしてしまうので、以下でご紹介する「Google Colabで試す」をおすすめします。
Stable Video Diffusionを実際に使ってみた

Stable Video Diffusionをもっと手軽に試すために、オンラインツールを使用することでGPUスペックによりますが、数分以内に高品質な動画素材を作成することが可能です。
たとえば、あるプロジェクトでは、風景画から季節の変化を示す短いビデオクリップが作成されました。
ぼーStable Video DiffusionのAIは、画像内の細部に注意を払いながら、自然な動きを付加して非常にリアルな変化を実現しました。
また別のケースでは、製品広告のために、商品画像から使用シーンの動画を生成し、効果的なマーケティング素材として活用されたケースなどがあげられます。
このような実践的な利用経験を通じて、Stable Video Diffusionの強力な機能とその応用可能性を実感することができます。
ぼーまた、使用する中で発見される課題や問題点を解決することで、より高度な使い方やカスタマイズが可能となります。
さらに、このツールを利用することで、自身のスキルを向上させ、より創造的なビジュアルコンテンツを作成することができるでしょう。
Google Colabで試す
Colabにアクセスしたら、メニューバーより「ランタイム>すべてのセルを実行」を選択します。
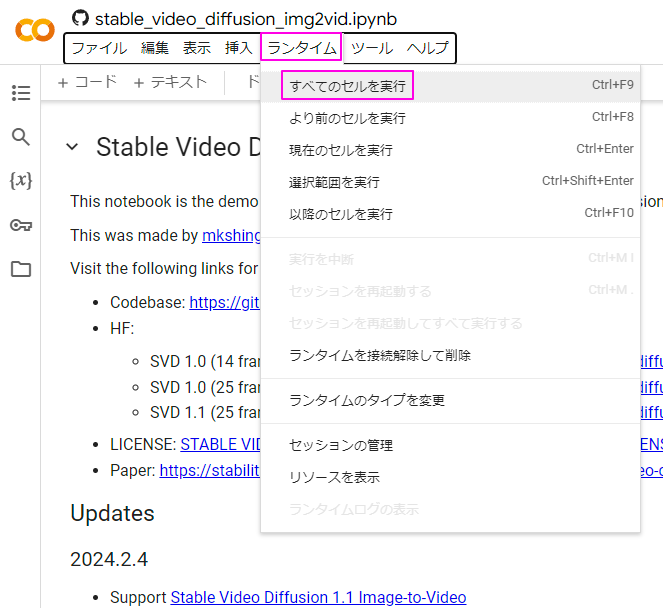
プログラムが順調に実行されていると、途中で下記画像のような「Tokenを入力してください」といったトークン入力画面が表示されます。
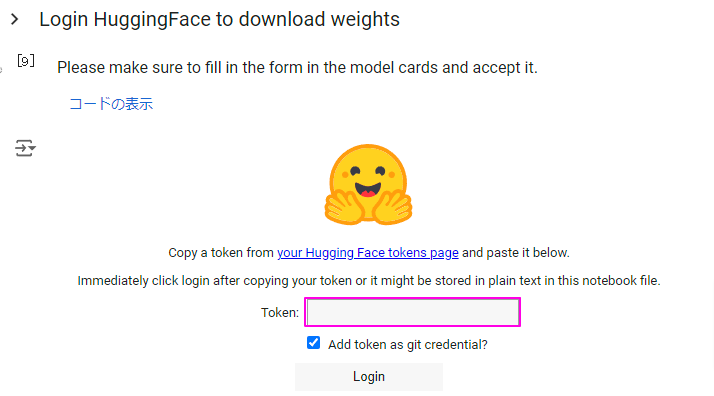
トークンを取得するには、Huggingfaceへのアカウント登録を行っている必要があります。
アカウント登録が完了したら、画面右上のユーザーアイコンをクリックし、表示されたメニューより「Settings」を選択します。
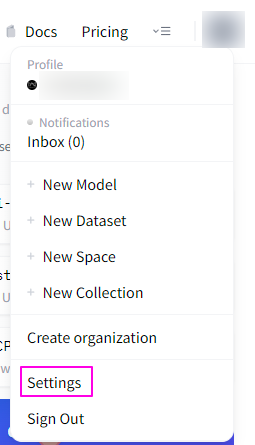
Settingsをクリックすると以下のようなページが表示されます。
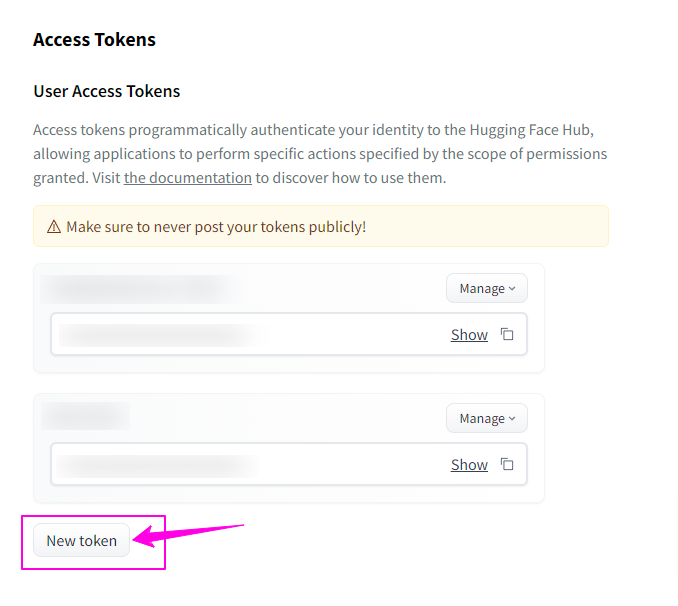
枠で囲ってある「New token」をクリックすると、下記のようなモーダルウィンドウが表示されます。
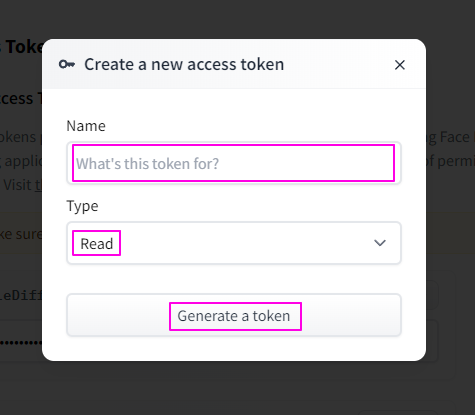
「Name」は何用に発行したのか後で分かるように、分かりやすいものにします。
そして「Type」は「Read」のままで問題ないので、「Generate a token」をクリックしてください。
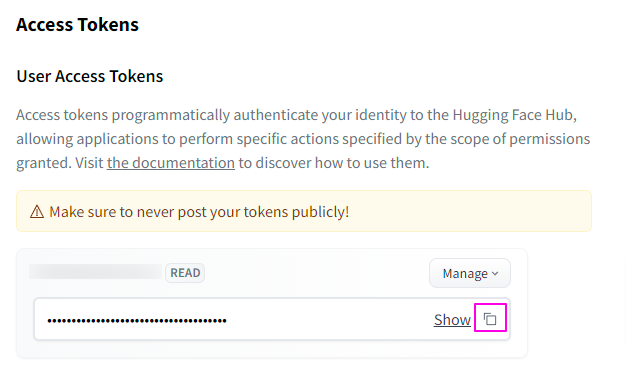
トークンが発行されると下記のような表示になるので、枠内のコピーボタンをクリックしてトークンをコピーしましょう。
Colabのページに戻り、先ほど表示されていたトークン入力欄にコピーしておいたトークンを貼り付けます。
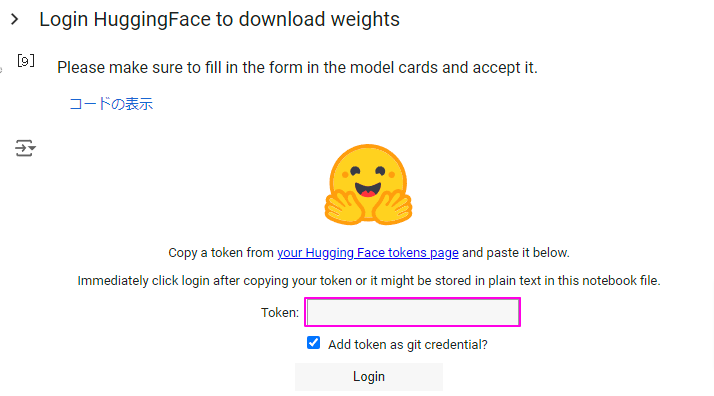
貼り付けたら「Login」ボタンをクリックします。
プログラムが全て準備完了となると以下のような「画像をアップロード」する場所が表示されるので、動画の元となる静止画をアップロードし「Run」をクリックしてください。
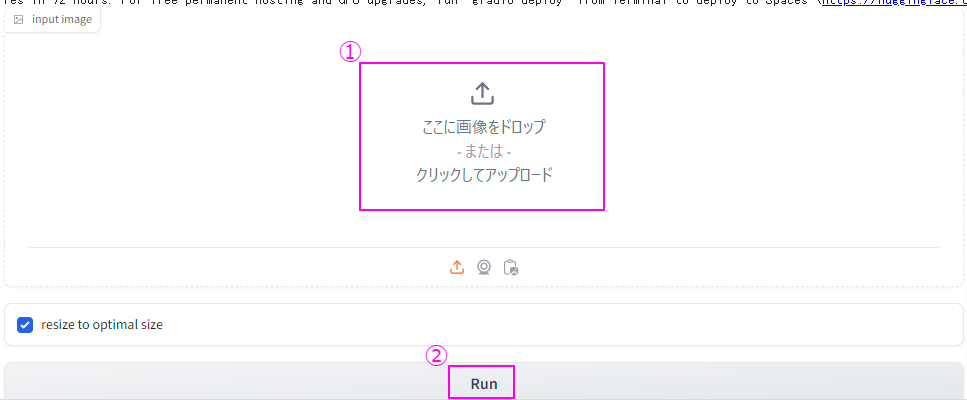
5,6分くらいで4秒程度の動画がその下の枠内に表示されるので確認してみましょう。
Stable Diffusion 3のテストで作成した画像をアニメーション化してみましたが、雲や魔法?の動きがそれっぽく出力されました。
意図したものに出来る可能性は低いので、気に入らない場合は、もう一度「Run」をクリックするか、別の画像でお試しください。
Stable Video Diffusionの活用事例3つ
最後に、Stable Video Diffusionの活用事例を3つ紹介していきます。
1. 映画およびアニメーション制作における特殊効果の向上

Stable Video Diffusionは、映画やアニメーション制作において革命的な効果をもたらしており、このツールを利用することで、背景の動きを自然に生成したり、キャラクターにリアルな表情を付加することが可能です。
従来の方法では、高品質なビジュアルエフェクトを作成するためには多大な時間と労力が必要でしたが、Stable Video Diffusionを活用することで、このプロセスが大幅に簡素化されます。
具体的には、AIが膨大なデータセットから学習し、その結果を基にして新しい映像を生成するため、手作業での編集やアニメーション作成の手間が大幅に削減されます。
たとえば、映画制作において、戦闘シーンやファンタジーの背景を生成する際に、Stable Video Diffusionを使用することで、非常にリアルな動きとディテールを持つ映像を短時間で作成することができます。
ぼー制作チームは、より創造的な部分に集中することができ、全体の制作時間とコストを削減することが可能です。
また、アニメーション制作では、キャラクターの表情や動きを自然に表現することが求められますが、Stable Video Diffusionはこれらの要求にも応えられるツールとなっています。
ぼーAIの力を借りることで、キャラクターの微細な表情や動きもリアルタイムで生成できるため、視聴者に対してより没入感のある体験を提供することができます。
さらに、Stable Video Diffusionは、制作の初期段階から最終段階までのすべてのプロセスにおいて活用可能です。
たとえばシナリオの段階でシーンのイメージを具体化するために使用したり、ポストプロダクションで特殊効果を追加するために使用するなど、クリエイターは自身のビジョンをより正確に反映した作品を作り上げることができるのです。
このように、Stable Video Diffusionは映画やアニメーション制作において、効率と品質を向上させるための強力なツールとなります。
2. 医療映像解析での精度向上

Stable Video Diffusionは、医療分野においてもその強力なツールとして注目されています。
ぼー特に、MRIやCTスキャンの画像解析において、その効果は顕著です。
従来の医療映像解析では、医師や技術者が大量の画像データを手動で解析する必要がありましたが、Stable Video Diffusionの技術を「Stable Video 3D」の導入により、このプロセスが大幅に効率化されました。
AIが画像データを基にして詳細な3D映像を生成するため、診断の精度が向上し、病気の早期発見や治療計画の策定に役立てることができます。
たとえば、がんの診断において、Stable Video 3Dは腫瘍の形状や位置を高精度で解析し、医師に提供することができます。
ぼー医師はより正確な診断を下すことができ、適切な治療法を選択する際の重要な情報を得ることが可能です。
また、心臓病の診断においても、AIが生成する詳細な3D映像を用いることで、血管の狭窄や異常を迅速に検出し、治療の効果をリアルタイムでモニタリングすることが可能です。
さらに、Stable Video 3Dは手術計画やシミュレーションにも応用されており、外科医は手術前にAIが生成した詳細な3D映像を参照することで、手術のリスクを最小限に抑えるための計画を立てることができ、手術の成功率が向上し患者の回復も早まることが期待されます。
また、学生や研修医に対しても、実際の手術映像を基にした教育コンテンツを提供することで、実践的なスキルを習得するための貴重なリソースとなります。
ぼーこのように、Stable Video Diffusionは医療分野における診断の精度向上、手術計画の改善、教育の質の向上に貢献しています。
今後もこの技術の発展により、さらなる医療の進化が期待されます。
3. 自動運転車の映像認識システムの改善

自動運転技術の進化に伴い、Stable Video Diffusionはその重要性を増し、自動運転車の開発において、映像認識システムの精度と安全性の向上は欠かせない要素です。
Stable Video Diffusionは、さまざまな道路状況や天候のシミュレーションビデオを生成する能力を持ち、運転アルゴリズムの訓練において非常に効果的です。
ぼーたとえば、悪天候時の運転シミュレーションでは、雨や雪、霧などの条件下での道路状況を再現し、自動運転システムがどのように対応するかを検証します。
AIが生成するこれらのビデオデータを用いることで、システムは多様なシナリオに対して適応力を高めることができます。
また、都市部や郊外、山間部など異なる環境での運転シミュレーションも可能で、より実際の運転環境に近いデータを基にしてアルゴリズムを最適化することも可能です。
さらに、歩行者や他の車両との衝突を回避するための映像認識システムの精度を向上させることができるなど、AIが生成するリアルなシミュレーションデータを使用することで、緊急時の対応や事故の予防策をより効果的なトレーニングできるようになったことで、自動運転車が実際の交通環境で安全に運行できるようになります。
開発コストと時間の削減にも貢献しており、従来の方法では、実際の道路で多くのテスト走行を行う必要がありましたが、AIによるシミュレーションを活用することで、テストの一部を仮想環境で行うことが可能なので、開発期間を短縮し、コストを削減することが可能です。
ぼー自動運転技術の進化において、映像認識システムの精度向上、安全性の強化、開発効率の向上に大きく貢献しています。
まとめ
Stable Video Diffusionは、その高度なビデオ生成能力によって、映画制作、医療分野、自動車産業など、多岐にわたる分野で有効活用されています。
この技術は、時間とコストを節約しながら、クリエイティブなビジョンを実現する強力なツールとして機能しており、今後もその応用範囲は広がっていくことが予想され、ユーザーがこれを利用する際には、料金体系や商用利用の可否、必要な技術要件を十分に理解することが成功への近道かもしれません。