
近年、AI技術の急速な進化により、音声処理の分野にも革命的な変化が起きています。
特にOpenAIが開発した最新音声モデルは、従来のモデルを超える精度と機能性で注目を集めています。
さらに、テキスト、画像、音声を統合的に処理できるGPT-4oシリーズの登場により、ビジネスや教育、エンターテインメントなど様々な分野で新たな可能性が広がっています。
本記事では、OpenAIの最新音声モデルの全容と、その具体的な活用法について詳しく解説していきます。

OpenAIの最新音声モデル「GPT-4o」とは?
GPT-4o(GPT-4 Omni)は、OpenAIが2024年5月に発表したマルチモーダルAIモデルです。
テキスト、画像に加えて音声の入出力にも対応しており、自然な会話や高度な音声認識・音声合成が可能になりました。
 ぼー
ぼー特に注目すべきは、音声機能の大幅な進化です。
ここでは、GPT-4oにおける音声関連の3つの主要モデルについてご紹介します。
GPT-4o Transcribe:高精度な音声認識モデル
GPT-4o Transcribeは、音声をテキストに変換する高精度な音声認識モデルです。
従来のWhisperモデルの技術をさらに発展させることで認識精度が向上し、単語誤り率(WER)が改善しました。
ぼーまた、100以上の言語に対応し、騒がしい環境下でも安定して音声を文字起こしできるといった強みがあります。
さらに、話し方のアクセントや話速にも柔軟に対応できるため、微妙なニュアンスや専門用語も正確にテキスト化することが可能です。
GPT-4o Mini Transcribe:軽量で高速な音声認識モデル
GPT-4o Mini Transcribeは、GPT-4o Transcribeの軽量・高速版として設計された音声認識モデルです。
モデルサイズが小型化されたことで、処理速度とコスト効率の両立を実現しながら、GPT-4o Transcribe同様に高精度なテキスト化を行うことが可能となっています。
ぼーまた、ほぼリアルタイムで音声を認識・処理できるため、素早いレスポンスが求められるシーンに最適です。
GPT-4o Mini TTS:自然な音声を生成するTTS(音声合成)モデル
GPT-4o Mini TTSは、テキストから自然な音声を生成するText-to-Speech(TTS)モデルです。
本物の音声データセットで事前トレーニングを行なっているため、微妙なニュアンスまで再現できる高精度な音声出力が可能です。
具体的には、自然な抑揚やリズム表現に加え、テキスト内容に応じた感情表現にも対応しています。
ぼー英語をはじめとする多言語での音声合成が可能で、声のトーンやスピード、ピッチなども細かく調整できる柔軟なカスタマイズ性が魅力です。
Whisperとの違いを比較
Whisperとは、2022年に公開された、OpenAIの従来の自動音声認識システムです。
ぼー多くのユーザーに利用されてきたモデルですが、GPT-4oシリーズとの間にはいくつかの大きな違いがあります。
| 比較項目 | Whisper | GPT-4o音声モデル |
|---|---|---|
| 主な対応機能 | 音声認識 | 音声認識 + 音声合成 |
| モーダル対応 | 音声のみの単一モーダル | テキスト・画像・音声を統合処理できるマルチモーダル |
| 文脈理解 | 限定的 | 高度な文脈理解により複雑な会話・専門用語にも対応 |
| 応答速度 | 標準的 | 高速(特にMini TTSはリアルタイム処理が可能) |
| 適した利用シーン | 録音音声の書き起こしなど | 会話AI、読み上げ、リアルタイム字幕など幅広い用途 |
Whisperは「書き起こし特化」のシンプルな用途に向いている一方、GPT-4oの音声モデルは「会話・応答・合成までをカバー」する次世代型といえるでしょう。
ぼー使用目的に応じて使い分けるのがポイントです。
【業界注目の理由】OpenAI音声モデルの強み
Whisperとの比較も踏まえ、GPT-4oシリーズの各モデルの特徴を簡単にご紹介してきました。
ここでは、なぜ今、業界がOpenAIの音声モデルに注目しているのか、その大きな強みをご説明します。
高精度なマルチモーダル処理
GPT-4oの最大の強みは、テキスト・画像・音声を統合的に処理できるマルチモーダル能力にあります。
例えば、音声入力に対して画像を参照しながら回答する、あるいは音声指示に基づいて画像を分析するといった、複合的なタスクが可能になりました。
ぼーこれにより、単一モーダルのAIでは対応が難しかった複雑なユースケースにも柔軟に対応できます。
自然な会話体験
GPT-4oの音声モデルは、これまで以上に人間らしい自然な会話に近づいています。
ぼーその大きな要因のひとつが、処理遅延の少なさです。
従来の音声AIでは、応答までにタイムラグが生じ、スムーズな会話を妨げていました。
しかしGPT-4oでは、低遅延での応答が可能となり、会話のテンポが格段に向上しました。
また、会話の切れ目を自然に判断し、適切なタイミングで応答できる点も、やりとりの自然さを高めています。
さらに、会話の流れを一時的に記憶し、前後の文脈を考慮した応答が可能になったことで、より人間らしくスムーズな対話が実現しました。
多言語・多方言対応
OpenAIの音声モデルは、100言語以上の音声認識と音声合成に対応しています。
特筆すべきは、単に多言語に対応しているだけでなく、各言語の方言や訛りにも対応可能な点です。
ぼー日本語においても、標準語だけでなく関西弁や東北弁などの方言も高精度で認識できるとされています。
さらに、音声認識と翻訳を組み合わせたリアルタイム音声翻訳も実現可能となり、国際的なビジネスやグローバルなコミュニケーションの在り方を大きく変える可能性を秘めています。
OpenAIの最新音声モデルの導入〜始め方
ここでは、OpenAIの音声モデルを自社サービスやプロジェクトに導入する手順をご紹介します。
OpenAIのサイト(https://openai.com/ja-JP/)にアクセスし、左側メニューから「APIプラットフォーム」を選択します。

「APIログイン」をクリックし、OpenAIアカウントにログイン、または新規登録を行います。
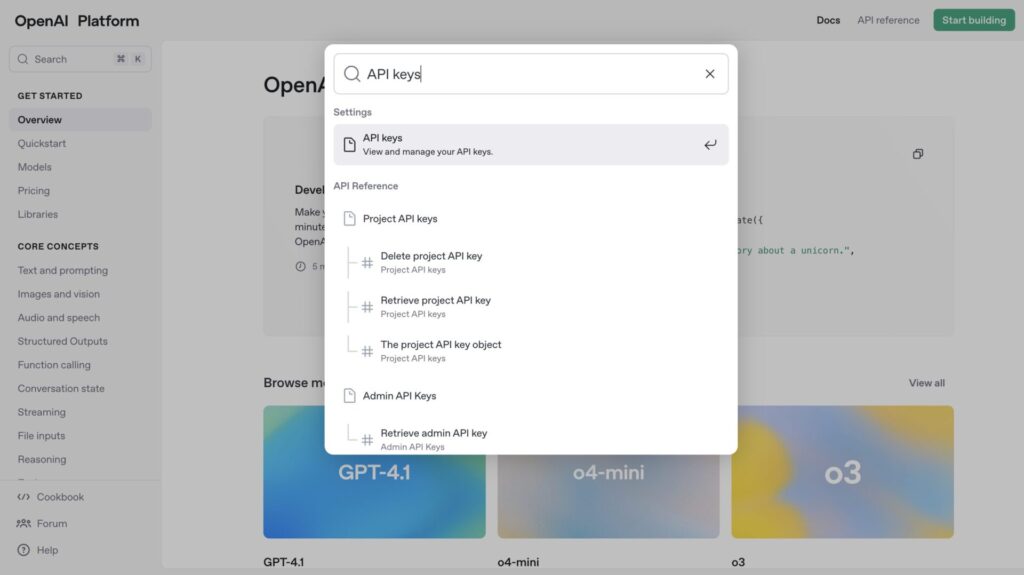
ログイン後、画面左上の「Search」バーに「API keys」と入力して検索します。
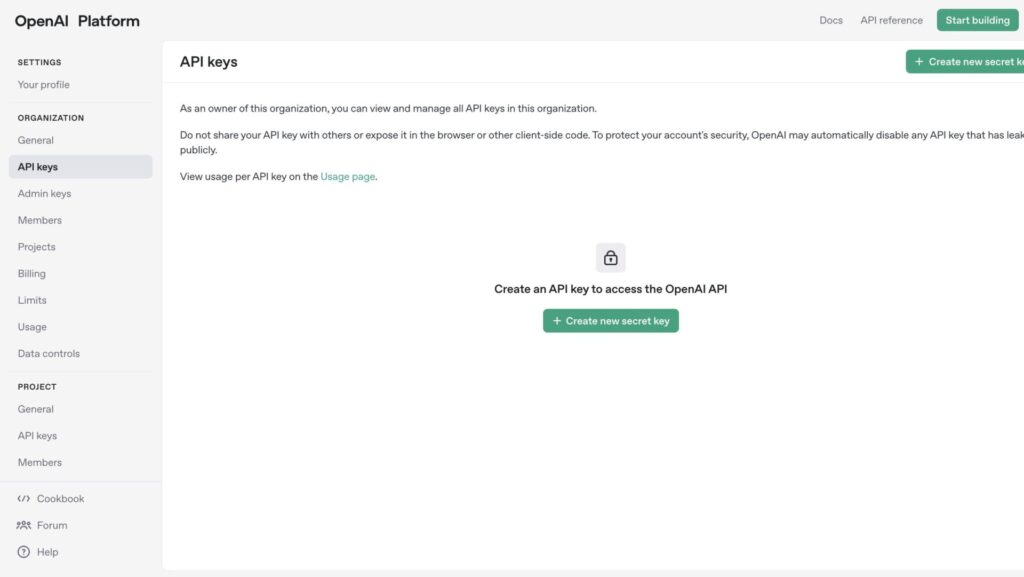
画面中央の「Create new secret key」ボタンをクリックし、新しいAPIキーを作成します。
「Owned by」は「You」、「Name」は任意で入力し、「Create secret key」で生成します。
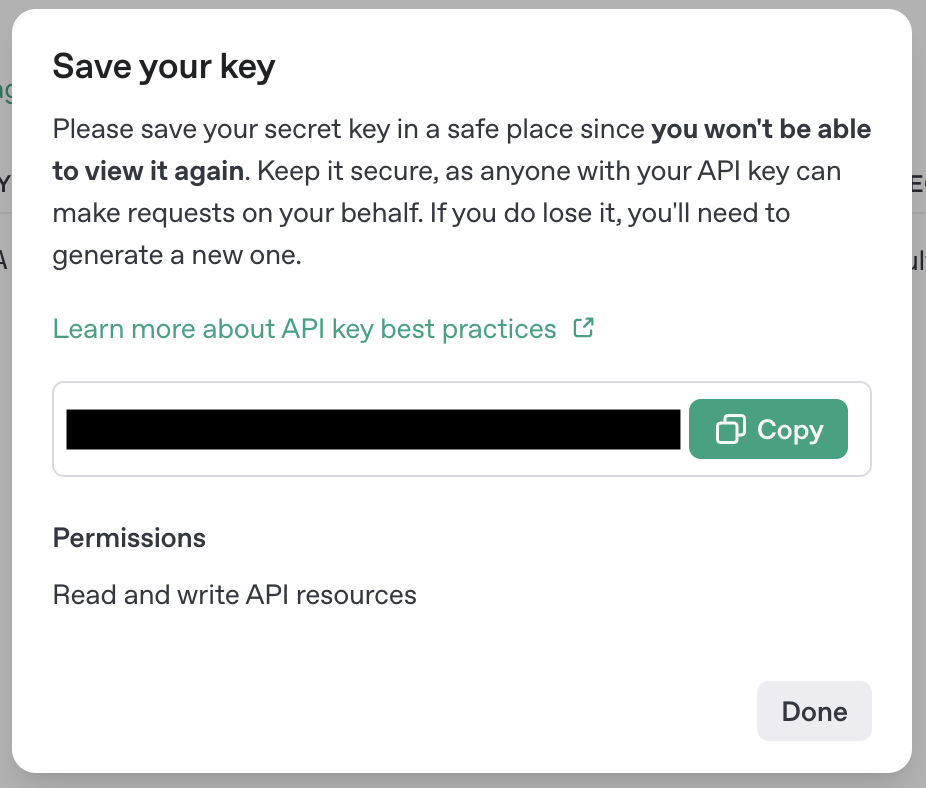 ぼー
ぼー以下は、Pythonで音声ファイルをテキストに変換する基本的なコード例です。
import openai
# APIキーを設定
openai.api_key = "YOUR_API_KEY"
# 音声ファイルをテキストに変換
def transcribe_audio(file_path):
with open(file_path, "rb") as audio_file:
transcript = openai.Audio.transcribe(
model="gpt-4o-transcribe",
file=audio_file,
language="ja" # 日本語の場合
)
return transcript.text
# 使用例
text = transcribe_audio("meeting_recording.mp3")
print(text)無料で試用できるデモサイト「OpenAI FM」
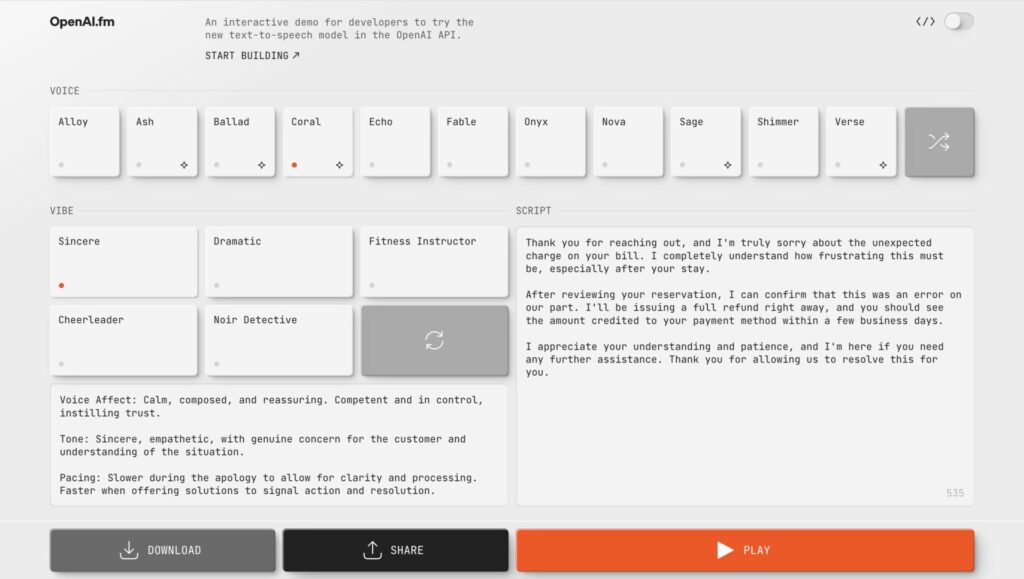
OpenAIは、音声モデルを誰でも気軽に試せるデモサイト「OpenAI FM」を提供しています。
このサイトでは、以下のような機能をブラウザ上で体験できます。
- 音声認識:マイクから話した内容をリアルタイムでテキスト化
- 音声合成:入力したテキストを自然な音声に変換して出力
- 音声翻訳:ある言語で話した音声を、他言語に翻訳して音声出力
- AIアシスタント:音声で質問すると、音声で回答してくれる会話体験
OpenAI FMは登録不要・無料で利用できるため、開発者だけでなく一般ユーザーも手軽に最新の音声技術を体験できます。
ぼーAPI導入前の検証や、導入検討の第一歩としてもおすすめです。
OpenAIの最新音声モデルの活用方法
では、OpenAIの音声モデルは実際にどのようなシーンで活用できるのでしょうか?
ここでは、具体的な事例と活用シーンをいくつかご紹介します。
ビジネスシーンでの活用事例
ビジネス分野で特に注目されているのが、業務の効率化です。
たとえば、日々の会議の内容をリアルタイムでテキスト化したり、重要なポイントを自動で要約したりと、記録業務の負担を大幅に軽減できます。
また、音声指示によるデータ入力や報告書作成の自動化にも応用でき、人的リソースの有効活用が可能になります。
ぼーさらに、コミュニケーション面でも大きな効果を発揮します。
社内においては、OpenAIを活用することで多言語コミュニケーションができ、国際会議やグローバルビジネスでのリアルタイムでの通訳も可能となります。
社外においても、24時間対応の音声AIアシスタントによる問い合わせ対応が可能となり、カスタマーサポートの面で役立てることができます。
教育現場での活用事例
教育分野では、個別最適化された学習体験の提供にOpenAIの音声モデルが活用されています。
たとえば、授業内容の自動記録や講義・テキストのリアルタイム翻訳はもちろん、音声を活用した学習支援にも効果的です。
具体的には、発音練習やインタラクティブ教材としての活用が挙げられ、24時間いつでも会話練習ができるのも大きなメリットです。
ぼーさらに、読み書きが困難な学習者向けの音声インターフェースとしても活用でき、教育のアクセシビリティ向上にも貢献します。
エンターテインメント分野での活用事例
エンターテインメント分野においても、OpenAIの音声技術の活用が広がりつつあります。
たとえば、音声コンテンツの配信サービスであるポッドキャストをはじめ、映像制作においても、ナレーションやボイスオーバーの自動生成に活用できます。
ぼーまた、映像制作の現場でも、ボイスオーバーやキャラクターボイスの自動生成など、クリエイティブな音声演出の実現に貢献できるでしょう。
OpenAIの最新音声モデルに関するよくある質問
ここでは、OpenAIの最新音声モデルに関するよくある質問に回答します。
- 商用利用は可能?
-
OpenAIの商用利用は可能です。
OpenAIの利用規約ではコンテンツの所有権限に関して、「アウトプットに関する権利、権原、及び利益がある場合、これらすべての権限をお客様に譲渡」すると記載されています。
 ぼー
ぼーただし、適用法令で認められる範囲と定められている点に注意しましょう。
- 日本語に対応している?
-
OpenAIの音声モデルは日本語に対応しています。
前述のとおり、標準語はもちろん、関西弁や東北弁などの方言や訛りにも一定の対応力があります。
また、敬語やビジネス用語、一部の専門用語も正確に認識・生成することが可能です。
ぼーそのため、日本語環境での会話アプリケーションや音声入力ツールにも安心して活用できます。
- 精度はどの程度?ノイズ環境でも使える?
-
OpenAIの音声モデルは非常に高い精度を誇り、騒がしい環境でも使用可能です。
従来のWhisperモデルと比べても、単語誤り率(WER:Word Error Rate)が大幅に改善されており、より正確な音声認識が可能となっています。
また、ノイズキャンセリング機能の強化により、周囲の雑音が多い状況でも安定した音声処理が実現されています。
まとめ
OpenAIの最新音声モデルは、音声認識と音声合成の両面で大きな進化を遂げています。
とくにGPT-4oシリーズは、従来のWhisperモデルからさらに発展し、高精度なマルチモーダル処理、自然な会話体験、多言語・多方言への対応など、さまざまな強みを備えたモデルとして、すでに多くの分野で活用が進んでいます。
今後は、ビジネス・教育・エンターテインメントなどの現場で、より革新的な活用が進展していくでしょう。
開発者や企業ユーザーはもちろん、一般の利用者もデモサイトやAPIを通じて手軽にAI技術を体験・導入できる環境が整いつつあります。
これからの音声AIの進化は、私たちの生活や働き方をさらに便利に、そして豊かにしてくれることでしょう。