
PCやスマートフォンの読み上げ機能、動画のナレーションなど、昨今の私たちの生活には「音声生成」が欠かせない存在になりつつあります。
こうした中、Googleが開発した生成AI「Gemini(ジェミニ)」が、音声生成とテキスト読み上げ技術の未来を大きく塗り替えようとしています。
2024年以降、Googleは Geminiを通して、より自然でリアルな音声をAIで生成できる技術を進化させました。
単なる「読み上げ」にとどまらず、人間らしい抑揚、感情表現などを含んだ音声生成を実現しています。
本記事では、Google Geminiが提供する音声生成の特徴や仕組み、使ってみた感想などをわかりやすく解説していきます。
本記事を読むことで、最先端の音声生成機能がしっかりとわかるようになりますよ。

Google Geminiの音声生成・テキスト読み上げとは?
Google生成AI「Gemini」は、文章や画像、動画といった機能を備えた次世代モデルとして注目をされてきました。
そして2024年に発表された「Gemini 2.5」では、テキストをリアルな音声へと変換できる音声生成機能が強化され、“ネイティブオーディオ”とも呼ばれる自然な読み上げが可能になりました。
従来の音声合成と比べて、Geminiの読み上げは発音の精度やイントネーションが飛躍的に向上し、まるで人間が話しているような自然な仕上がりを実現しています。
 ぼー
ぼーまた、読み上げるスピードや声のトーンを状況に応じて調整できる柔軟性もあり、ニュースのナレーションやYouTube動画、視覚障害者の情報支援など、幅広いシーンでの活用が期待されています。
Googleはこの機能を通じて、テキストだけでなく「声」までも創り出せるマルチモーダルAIとして、Geminiの可能性をさらに広げています。
Google GeminiのTTS機能の概要
Google Geminiに搭載されたTTS(Text-to-Speech:音声合成)機能は、2024年登場のバージョン2.5で大きな進化を遂げました。
現在のGeminiのTTSは、大きく分け、「リアルタイム音声ダイアログ」と「制御可能なテキスト読み上げ」の2種類が用意されています。
リアルタイム音声ダイアログ
ユーザーとAIが音声で自然な双方向会話を行うことが可能で、レスポンスの速さと発話の滑らかさに優れています。
制御可能なテキスト読み上げ
スピード・トーン・感情の強弱などを細かく調整でき、読み上げるコンテンツや目的に合わせたカスタマイズが可能。
ぼーGeminiのTTSは、数百時間以上にわたる高品質な音声データで学習されており、人間らしい抑揚やブレス、間の取り方まで再現できるのが大きな特長です。
また、Geminiの強みであるマルチモーダル処理と連携することで、文脈や視覚情報を反映した読み上げも実現。従来のTTSを超える、より自然で柔軟な音声生成が可能になっています。
Google Geminiで音声読み上げを使う方法
Geminiの音声読み上げ機能は、「Google AI Studio」から簡単に体験できます。以下の手順で進めてみましょう。
まずは、Google AI Studioにアクセスします。
ご自身のGoogleアカウントでログイン。もしアカウントを持っていない場合には、新規作成してからログインしましょう。
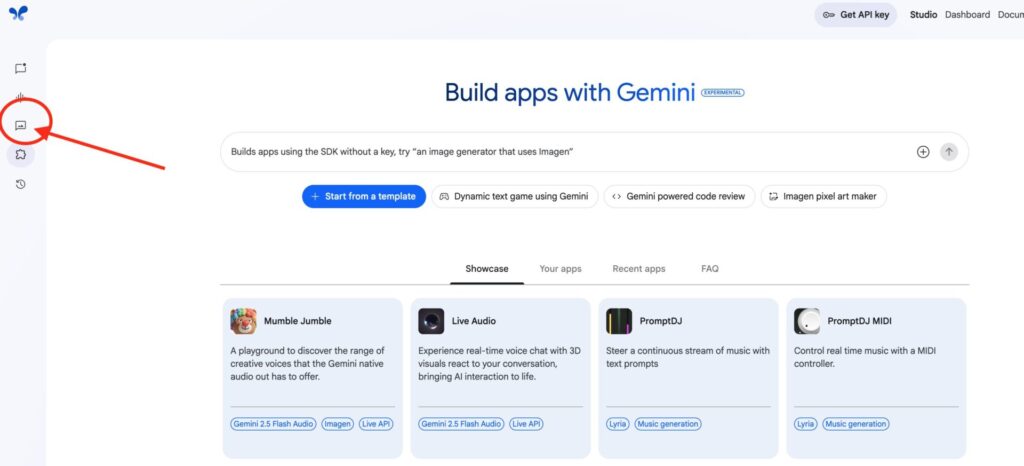
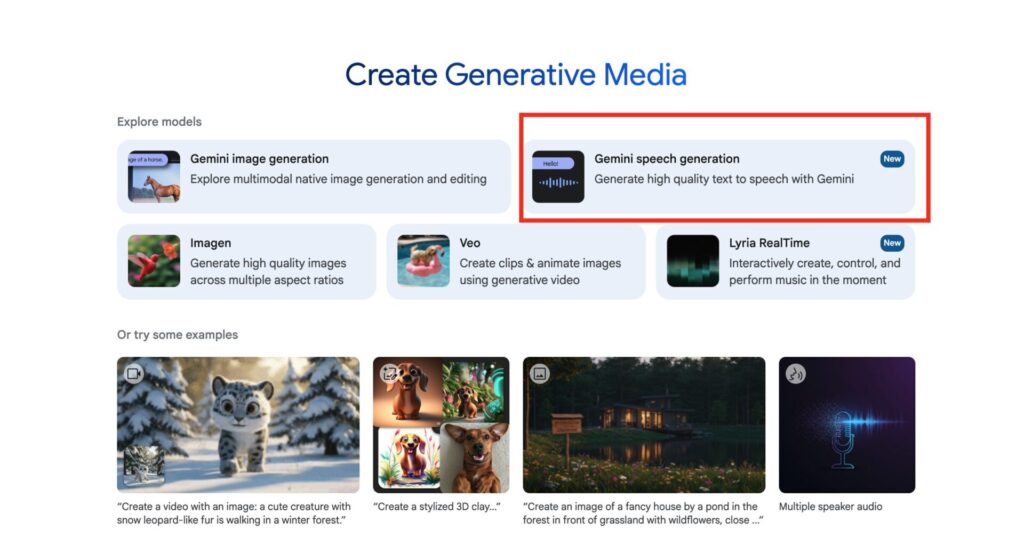
「Generate Media」メニュー内の赤枠で示した「Gemini speech generation」セクションをクリックします。ここで、音声読み上げ機能を立ち上げることができます。
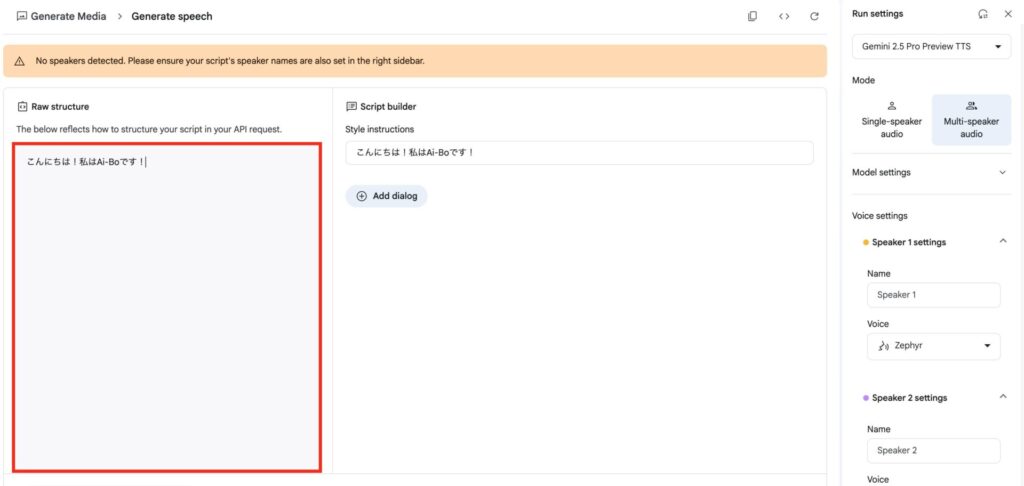
赤枠で示したテキスト欄に、読み上げてほしい文章を入力しましょう。
入力が完了したら、再生ボタンをクリックすることで、Geminiによる読み上げ音声を確認できます。
Google AI Studioで使ってみた感想
実際にGoogle AI Studioにて「Gemini TTS」を使ってみたところ、そのナチュラルな読み上げに驚かされました。
ぼー従来のTTSによくある、抑揚のない無機質な音声とはまったく異なり、本物のナレーターが話しているかのような自然な声が生成されます。
とくに日本語の読み上げは難易度が高いと言われていますが、Gemini TTSは、期待を大きく超える滑らかさと流暢さで、日本語の文章をスムーズに読み上げてくれました。
人間が話すときに自然に入れるブレスや間(ま)も違和感がなく、まるで生身の人間がその場で読んでいるように感じられます。
ぼー個人的には、YouTubeのナレーション音声としての活用に非常に適していると感じました。
情報をやさしく、自然に伝えたい場面で、とても心強いツールになるはずです。
他のTTSツールとの比較と選び方
数あるTTS(テキスト読み上げ)ツールの中で、Google Geminiはどのような特徴を持ち、他のツールとどう違うのでしょうか?
ここでは、主要サービスと比較しながら、用途別の選び方やGeminiを選ぶメリットについて解説します。
Gemini vs Google Cloud TTS vs 音読さん
TTSツールにはさまざまな種類がありますが、目的や使用環境に応じて選ぶことが重要です。
この項目では、「Gemini」「Google Cloud TTS 」「 音読さん」の3つを比較して、以下表として提示しました。
| Gemini | Google Cloud TTS | 音読さん | |
|---|---|---|---|
| 特徴 | マルチモーダルAIと統合された高精度の音声生成。 リアルタイム会話や感情表現も可能。 | 商用向けに安定したAPIを提供。WaveNet技術で高品質。 | Webで無料・手軽に使える日本語特化のTTS。VTuber風の声も選択可。 |
| 対応言語 | 英語中心 (今後多言語展開予定) | 100以上の言語と方言に対応 | 日本語のみ |
| カスタマイズ性 | 声のトーン・速度・感情表現などを高度に調整可能 | SSMLによる詳細な調整が可能 (音量・速度・感情など) | 話者の選択・速度調整は可能だがカスタマイズ性は限定的 |
| 料金 | 正式提供前のため不明 (今後Gemini Advancedなどに統合か) | 100万文字/月までは無料、それ以降は従量課金(例:$4/100万文字) | 無料 (商用利用には制限あり) |
ぼー目的に応じて最適なツールを選び、自分に合った音声体験を取り入れてみましょう。
利用シーン別おすすめツール
TTSツールは、利用目的によって最適な選択が必要になります。
以下に代表的な利用シーンと、それぞれに適したツールを整理しました。
| 利用シーン | おすすめツール | 理由・特徴 |
|---|---|---|
| 動画ナレーション | Google Gemini TTS | 感情・抑揚・間の取り方が非常に自然。リアルな話し声に近く、YouTubeやプロモーション動画に最適。 |
| オーディオブック・朗読コンテンツ | Google Gemini TTS | 感情表現や話者ごとの演じ分けが可能。登場人物の会話にも臨場感が出せるため、朗読用途に最適。 |
| 多言語対応コンテンツの作成 | Google Cloud TTS | 100以上の言語・方言に対応。商用でも使える高い安定性と品質。多言語Webやアプリに◎。 |
| 教育・資料の読み上げ | 音読さん | Web上で無料&手軽に使える日本語TTS。教科書や資料の読み上げ、視覚支援に便利。非エンジニアにもやさしい。 |
TTSツールは「何に使いたいか」によって選ぶべきサービスが変わります。
ぼー性能や価格だけでなく、感情表現・対応言語・手軽さといった視点で比較し、最適なツールを選びましょう。
Google Geminiの音声生成に関するよくある質問
この項目では、Google Geminiの音声生成に関するよくある質問をまとめました。
まだ利用するには疑問が残る、という方はぜひ参考にしてみてください。
無料で使える?料金は?
ぼーGoogle AI StudioやGemini APIの無料枠(Free Tier)では、レート制限の範囲内でTTS機能を無料で試すことができます。
商用利用や大量の音声出力には有料プランが必要で、TTS出力の料金は100万トークンあたり10ドルが目安です
音声の雰囲気や感情はどこまで調整できる?
Google GeminiのTTS機能は、声の「雰囲気」や「感情」をかなり精密に調整できます。
たとえば、以下のような自然言語による指示で調整ができます。
- 囁くように
- 興奮気味に
- 悲しげに など
ぼーこれにより、声のトーンや抑揚、話し方のスタイルを直感的にコントロールすることができ、単なる読み上げではなく、人間らしい感情のこもった音声生成が可能になります。
特にGemini 2.5では、複数の話者にそれぞれ異なる感情や話し方を割り当てることも可能になっており、オーディオブックや朗読コンテンツの制作にも活用が広がっています。
さらに、API経由での利用では、以下のような要素の微調整も自然言語ベースで指示できます。
- 話す速度(速く・ゆっくり)
- アクセントの強弱
- 間(ま)の取り方やポーズの位置
開発者は複雑な数値パラメータを操作せずに、自然な文章で指示を出すだけで音声の雰囲気を自在に調整できるのも魅力です。
GeminiのTTSは、単なる「読み上げ」を超え、感情やスタイルまで精巧に再現できる柔軟性と表現力を持った次世代のAI音声ツールと言えるでしょう。
文字起こしや翻訳との連携は?
Google Geminiは音声生成(TTS)だけでなく、文字起こしや翻訳との連携にも非常に優れたマルチモーダルAIです。
Gemini 2.5では、音声ファイルやYouTube動画をアップロードして、文字起こしが可能になり、多言語翻訳も一連の流れで自動対応できます。
たとえば、Google AI StudioやGemini APIで「英語を日本語に訳して字幕化して」といった指示を与えれば、一括処理できるような柔軟性があるのも特徴です。
ぼーGeminiは「文字起こし→翻訳→再音声化」の流れをスムーズに統合し、動画コンテンツ制作や多言語対応に非常に適したプラットフォームになっています。
生成した音声は保存やストリーミングができる?
Google Geminiの音声生成は、生成した音声をファイルとして保存したり、ストリーミング再生したりすることが可能。
ぼーたとえば、Gemini APIを使えば、生成された音声をWAV形式でローカルに保存することができます。
Google公式では、PythonやNode.jsのSDKを用いた保存用のサンプルコードも提供されており、バイナリデータとして取得した音声を簡単にファイル化できます。
さらに、GeminiのLive APIを使えば、リアルタイムで音声をストリーミング出力しつつ、ユーザーと双方向の会話形式で音声を送受信することも可能です 。
また、Geminiアプリで生成された「Audio Overview」は、再生だけでなく、リンク共有やダウンロードも対応しています。
ぼー音声生成後に自分の使いたい用途に合わせて、保存・ストリーミング・共有・再生など柔軟に選べる点が大きな魅力と言えるでしょう。
まとめ
本記事では、Googleの次世代生成AI「Gemini」に搭載されたTTS(音声生成)機能の特徴や実際に使ってみた感想などを解説しました。
Geminiは、マルチモーダルAIとして進化を続ける中で「ネイティブオーディオ」機能を統合。
リアルタイムでの音声対話や、感情のこもった自然な読み上げが可能となり、従来のTTSとは一線を画す性能を実現しています。
声のトーンやスピード、感情表現までも細かく調整できる点は、動画のナレーションや教育コンテンツ、または多言語展開にも最適と言えるでしょう。
音声生成技術は今後さらに進化が期待されている分野です。
Geminiの活用を通じて、情報発信や表現の可能性がこれまで以上に広がっていくことでしょう。