
OpenAIが開発した音声認識AI「Whisper」は、その精度の高さから注目を集めています。
ただ、「Whisper」と聞いて以下のように思う方もいらっしゃるのではないでしょうか。
- 「Whisperって聞いたことあるけど、よく知らない…」
- 「Whisperをどう使えば、文字起こしできるの?」
本記事では、Whisperの概要、機能、使い方、注意点、よくある質問などを詳しく解説するので、ぜひ最後までご覧ください。

OpenAIが開発した「Whisper」でできること
「Whisper」とは、OpenAIが2022年9月にリリースした最先端の音声認識AIであり、音声認識や音声翻訳などが可能です。
Whisperは英語をはじめ、日本語を含む多言語の音声を高精度に文字起こしするだけでなく、翻訳機能も搭載し、音声処理の幅広いニーズに対応します。
具体的には、以下の特徴があります。
- 高精度な文字起こし:ノイズが多い環境や早口言葉でも、高い精度で音声を文字に変換します。
- 多言語対応:英語に加え、日本語、中国語、フランス語など、様々な言語に対応しています。
- 翻訳機能:音声を認識した上で、別の言語に翻訳することができます。
- オープンソース:ソースコードが公開されているため、研究開発やカスタマイズに活用できます。
Whisperの文字起こしの精度について
Whisperの文字起こしの精度は、モデルサイズによって異なります。
 ぼー
ぼーモデルサイズが大きくなるほど、精度は高くなりますが、処理時間も長くなります。
具体的には以下のモデルがあります。
- tiny:最も小さいモデルで、処理は速いが精度は最も低い。漢字、カタカナ、平仮名の書き起こしが不十分な場合が多い。
- base:tinyよりも精度が高く、処理速度も比較的速い。漢字・カタカナ・平仮名の書き分けが上手くいっているが、誤字が存在する。
- small:標準のモデルで、精度と処理速度のバランスが取れている。カタカナの書き起こしが不完全な場合がある。
- medium: 高精度な文字起こしが求められる場合におすすめのモデルだが、処理速度が遅くなる。ほとんどの音を正確に文字起こしでき、句読点なども適切である。
- large:最も精度が高いモデルだが、処理速度も非常に遅くなる。ほぼ全ての音を正確な日本語として書き起こすことができる。
用途に応じて適切なモデルサイズを選択しましょう!
Whisperの料金体系について
WhisperはGoogle ColaboratoryやHugging Faceを使えば、無料で使えます。
ぼーAPI経由で利用すると有料になりますが、料金は1分ごとに0.006ドル(約1円)であり、比較的安価です。
【簡単】Whisperの使い方【Google Colaboratory】
Whisperは、Google Colaboratoryと呼ばれるクラウド環境を用いて、利用することができます。
初心者の方でも簡単に実行できるので、是非参考にしてください。
まずは、Google Colaboratoryを開き、「ノートブックを新規作成」を選択。
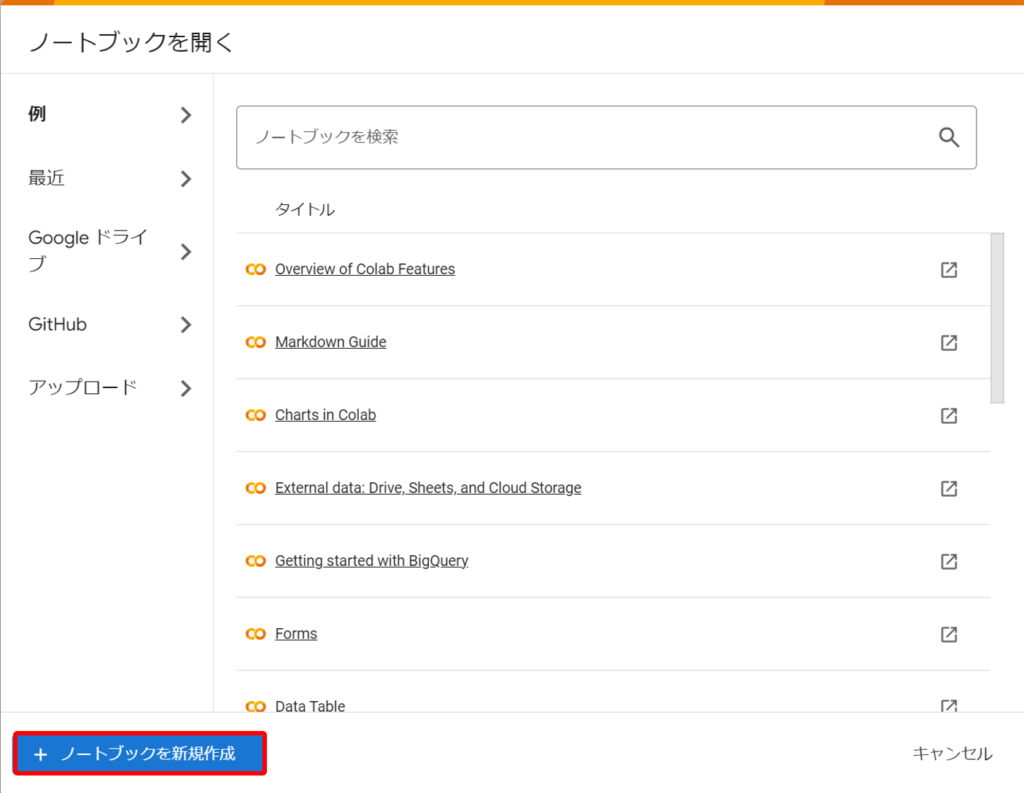
続いて、編集タブの「ノートブックの設定」をクリック。
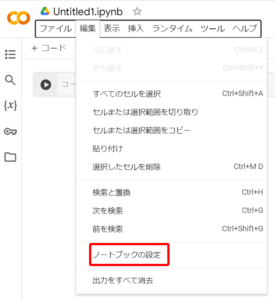
「ハードウェア アクセレータ」を「T4GPU」に設定して、右下の保存をクリックすれば環境設定は完了。
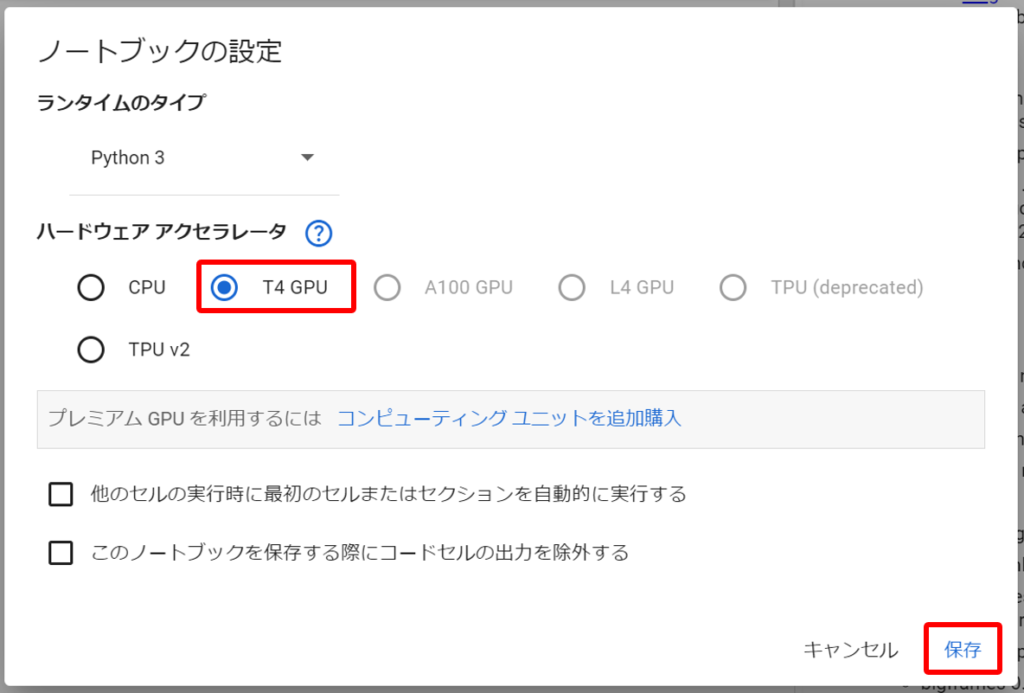
以下のWhisperのインストールコードを入力し、左側の実行ボタンをクリック。
!pip install git+https://github.com/openai/whisper.git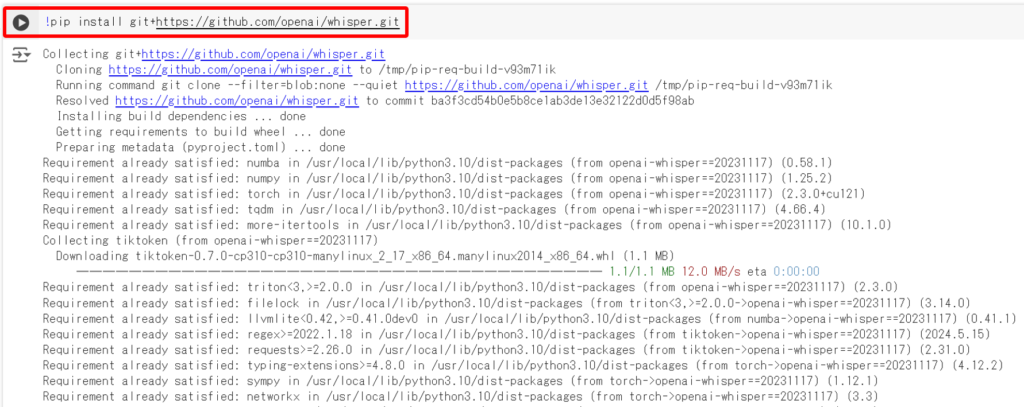
続いて、以下のコードを入力し、左側の実行ボタンをクリック。
import whisper
次に、画面左側の①のファイルマークから②のアップロードボタンをクリックし、文字起こしをしたい音声データをアップロードする。(今回は、“364262565279941.mp3”のファイル)
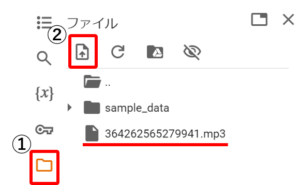
最後に、以下のコードを入力し、左側の実行ボタンをクリック。
※今回、モデル名は“base”、ファイル名は“364262565279941.mp3”で実行。
model = whisper.load_model(“モデル名”)
result = model.transcribe(“ファイル名”)
print(result[“text”])
入力した音声ファイル:関東・甲信地方の天気は、日中は各地で晴れる見込みです。午後は山の一部でにわか雨がありますが、平地で雨が降ることはなさそうです。東京は32度、さいたまは33度と今年一番の暑さ、横浜は30度と今年初めての真夏日になりそうです。お出かけの際は熱中症対策を忘れずに!
出力された文字起こし:監督、更新地方の天気は、日中は各地で晴れる見込みです。午後は山の一部でに若雨がありますが、平地で雨が降ることはなさそうです。東京は32度、最多まは33度と今年1番の厚さ、横浜は30度と今年初めての真夏日々になりそうです。おでかけの際は熱中小対策を忘れずに。
ぼー所々、漢字の変換ミスが見られますが、大部分は問題なく文字起こしできていることが確認できました。
より高精度のモデルを使用すると誤字も少なくなるかと思います。
【応用】Whisperをローカル環境で使う方法
WhisperはGoogle Colaboratory以外にも、ローカルインストールして、Pythonで利用することもできます。
AIモデルをローカル環境で使用するメリットは、外部に対する秘匿性、機密性を最大限担保できる点です。
ぼー※前提として、PythonとGitはインストールされている必要があります。
Powershellを管理者権限で起動し、「Set-ExecutionPolicy RemoteSigned」と入力して実行。
その後、「Y」と入力して実行し、powershellを閉じます。
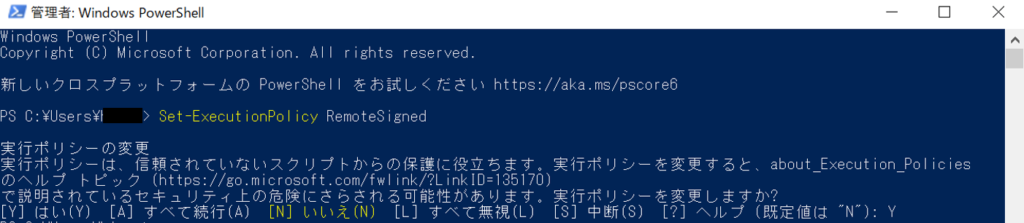
任意の場所に「Whisper」というフォルダを作成し、下図のようにパスを通した形でPowershellを起動(作成したフォルダ内でタスクバーにpowershellと入力して実行する)し、「python -m venv venv」と入力して実行。
ぼーその後、「./venv/scripts/activate」と入力して実行し、作成した仮想環境をアクティベートします。

次に、Whisper本体のライブラリをインストールします。
「pip install git+https://github.com/openai/whisper.git」と入力して実行すれば、インストールが開始します。
また、ffmpegライブラリのインストールを行います。
こちらのサイト(https://github.com/BtbN/FFmpeg-Builds/releases)から、「ffmpeg-master-latest-win64-gpl.zip」ファイルをダウンロードして、解凍し、任意のフォルダに設置。
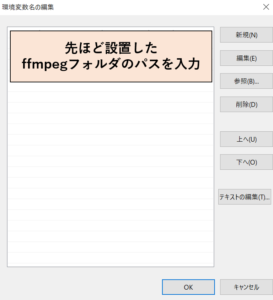
環境変数設定を開き(検索窓から環境変数を検索)、ユーザー環境変数内の「Path」の編集をクリックします。
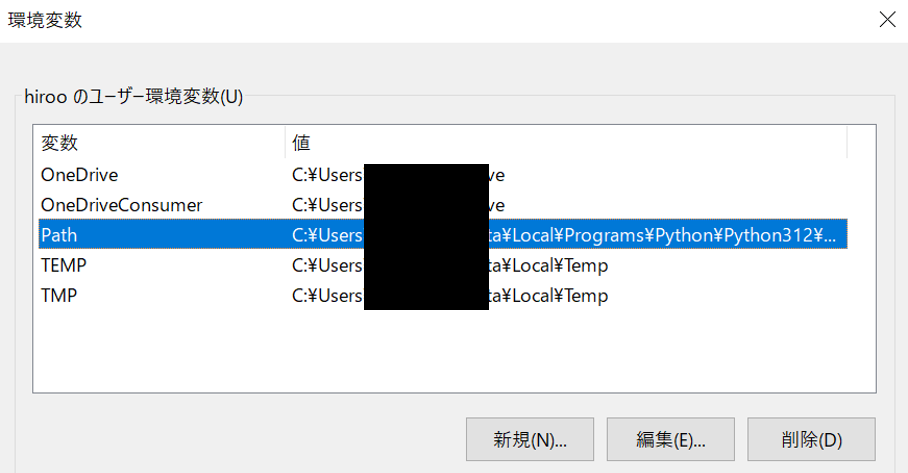
先ほど設置したffmpegフォルダのパスを入力してOKをクリックします。
「Whipser」フォルダにパスを通した形でpowershellを起動し、「./venv/scripts/activate」と入力して実行することで、仮想環境をアクティベートします。

最後に「whisper –model (モデル名) –language Japanese (対象ファイルのパス)」と入力して実行すれば、音声ファイルの書き起こしが実行されます。
ぼー※モデル名と対象ファイルのパスは具体的な名称を記載してください。
Whisperを使って文字起こしをする際の注意点
Whisperは高精度な文字起こし機能を備えていますが、完璧なツールではありません。以下の点に注意して利用する必要があります。
1. 音質の影響
Whisperは音声認識AIであるため、音質がクリアなほど、精度の高い文字起こしが可能になります。ノイズが多い環境や、早口言葉など、音質が悪い場合は、精度が低下する可能性があります。
2. 話者数の影響
Whisperは、基本的に1人の話者の音声を認識するように設計されています。複数人の会話の場合は、誰が話しているのかが区別できない場合があり、誤認識が発生する可能性があります。
3. 専門用語の影響
Whisperは、一般的な単語やフレーズであれば、高精度に認識することができます。しかし、専門用語や業界用語など、あまり使われていない単語の場合は、誤認識される可能性があります。
4. 長時間の音声
Whisperは、長時間の音声ファイルを処理する場合、処理時間が長くなることがあります。また、長時間の音声の場合は、途中で認識が途切れる可能性もあります。
5. セキュリティ
Whisperは、OpenAIが提供するクラウドサービスです。そのため、音声ファイルをアップロードする際には、セキュリティ対策に注意する必要があります。
ぼー会議の議事録や、講義のレポートなどをより簡単に作成したい方は、次章で紹介するおすすめの文字起こしツールを使ってみてください。
Whisper以外におすすめの文字起こしツール
ここでは、Whisper以外に、文字起こしに便利な機能が搭載されたツールを3つ紹介します。
| ール名 | 無料枠 | 要約機能 | 話者分離 | 対応環境 | セキュリティ |
|---|---|---|---|---|---|
| Notta. おすすめ! | 月120分 | 〇 | 〇 | Zoom / Teams / Meet / Webex | ISO 27001認証 |
| PLAUD おすすめ! | 月300分 | ◎ | 〇 | 専用デバイス+Zoom連携 | AES-256暗号化 / 学習不使用 |
| toruno | 累計3時間 | △ | 〇 | Zoom / Teams / Meet | 国内法人利用多数 |
Notta|文字起こしに必要な機能が全部入り

Nottaは、文字起こしに必要な機能が多く搭載されているツールです。
ぼーたとえば、複数人で会議をする際は、それぞれの話者を判別して、誰が話したのか分かる状態で文字起こしされます。
また、文字起こししたテキストを、AIが要約する機能も付いています。これらの機能を使えば、会議の議事録が一瞬で完成するでしょう。
ぼー気になる文字起こしの精度ですが、認識率は驚きの98.86%!
文字起こし後の、人の手による修正の時間も削減可能です。
また、Android/iPhone用のアプリが用意されているので、外出先での打ち合わせでもNottaを利用できます。
さらに、Webブラウザの「Chrome」の拡張機能でも利用できます。拡張機能は、面倒な設定は不要で、Webページの音声をリアルタイム文字起こしが可能。
Nottaは、仕事で文字起こしをすることが多く、業務を大幅に改善したい人におすすめです。

PLAUD|録音だけでOK!文字起こし&議事録作成を自動化する最強AIツール

PLAUDは、録音から文字起こし、要約、マインドマップ作成までを自動でこなす、高性能なAIボイスレコーダー&アシスタント。議事録作成にかかる時間と手間を大幅に削減できます。
文字起こしにはMicrosoft Azureの高精度エンジンを採用し、日本語を含む112言語に対応。
ぼー話者ごとの自動識別にも対応しているため、複数人の会議でも「誰が何を言ったか」がひと目で分かります。
さらに、要約・分析にはGPT-4やClaudeといった最新AIを活用。録音内容から要点を自動で抜き出し、わかりやすく整理された要約文やマインドマップを生成してくれます。
録音データはすべて暗号化され、AIの学習には使われない仕組み。セキュリティ面でも信頼性が高く、実際に医療現場でも活用されています。
ぼーなお、PLAUDの文字起こしや議事録作成機能を使うには、以下のいずれかのデバイスが必要です。
- PLAUD NOTE(カード型)
- PLAUD NotePin(ウェアラブル型)
どちらも専用アプリと連携することで、録音後すぐにテキスト化と要約が可能に。スタータープラン(無料)なら、月300分まで文字起こし&要約が無制限で使えるため、まずは気軽に試してみたい方にもぴったりです。
\今ならクーポンコード利用で5%オフ!:AFFPLAUD25 /

toruno|累計3時間の文字起こしが無料でできるAI

torunoは、無料で3時間分の文字起こしを利用できる、AI議事録自動作成ツールです。
議事録の文字起こしだけでなく、会議中に共有された資料をそのままキャプチャして保存できるのが大きな特長。資料を見逃す心配がありません。
ぼーさらに、突然の会議でもすぐに記録を始められるため、事前準備がいらないのも便利です。
無料プランではAI要約が使えず、有料プランでも一部のみ対応しているので、利用前にチェックしておきましょう。
Whisperに関するよくある質問
最後にWhisperに関するよくある質問とその回答についてピックアップしてご紹介していきます。
Q: Whisperのアプリはある?
Whisperの公式アプリはリリースされていません。
ぼーGoogle ColaboratoryやHugging Faceを使うとブラウザ上で利用することができます。
Q: Whisperを使った文字起こしは無料?
Google ColaboratoryやHugging faceを使えば、無料で使えます。
API経由で利用すると有料になりますが、料金は1分ごとに0.006ドル(約1円)であり、比較的安価です。
Q: Whisperの文字起こしの上限はある?
Whisperが文字起こしできるファイルサイズは25MBまでとなっています。
ぼーファイルサイズが25MBよりも大きくなってしまう場合は、ファイルを分割するなどの対策が必要です。
Q: Whisperの日本語精度は高い?
日本語の文字起こしの精度は「単語誤り率」の順位で6位の「5.3%」となっており、他の言語に比べて高い精度で文字起こしができます。
まとめ
それでは本記事をまとめます。
- 「Whisper」はOpenAIがリリースした最先端の音声認識AIであり、高精度な文字起こしが可能。
- Whisperのモデルサイズが大きくなるほど、精度は高くなるが、処理時間も長くなる。
- WhisperはGoogle ColaboratoryやHugging Faceを使えば、無料で利用可能。
Whisperは、高精度な文字起こし機能と翻訳機能を備えた、革新的な音声認識AIです。
本記事によってWhisperを理解し、議事録や文字起こしに活用することで、皆様にとって少しでも役立つ情報となれば幸いです。
